Optimieren Sie die Leistung Ihrer API
Antworten Ihre APIs langsam?
Eine schlechte API-Performance kann sich auf die Benutzererfahrung und Geschäftsbetriebe auswirken.
Identifizieren Sie Leistungsprobleme.
Analysiere API-Metriken, validiere Payloads und verfolge Antwortzeiten.
Lösungen für robuste APIs
Nutzen Sie LoadFocus für umfassende Beratung zur Verbesserung der Leistung und Zuverlässigkeit von APIs.
Vorteile der Echtzeit-API-Überwachung
Warum sich auf die Überwachung von APIs konzentrieren?
Effiziente APIs verbessern die Benutzererfahrung und Geschäftsabläufe.
Maßgeschneiderte Überwachungsstrategien
Erhalten Sie Einblicke, die spezifisch für die Leistung Ihrer API sind und Hinweise zur Verbesserung enthalten.
Über Geschwindigkeit und Betriebszeit hinaus
Verwenden Sie LoadFocus, um die Zuverlässigkeit von APIs zu verbessern, Ausfallzeiten zu reduzieren und die Gesamtqualität des Services zu verbessern.
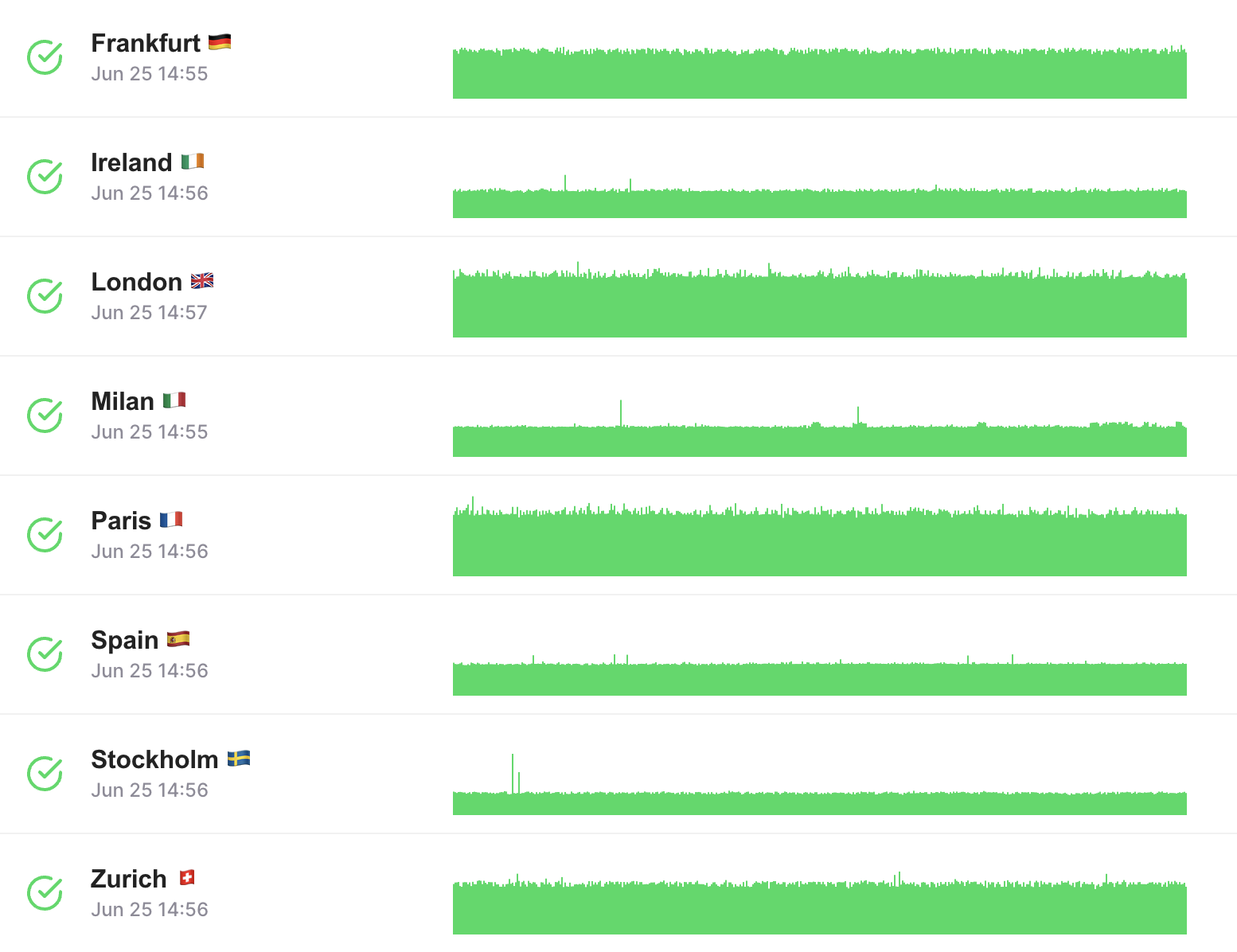
Umfassende API-Gesundheitsanalyse
Stellen Sie sicher, dass Ihre APIs immer verfügbar sind.
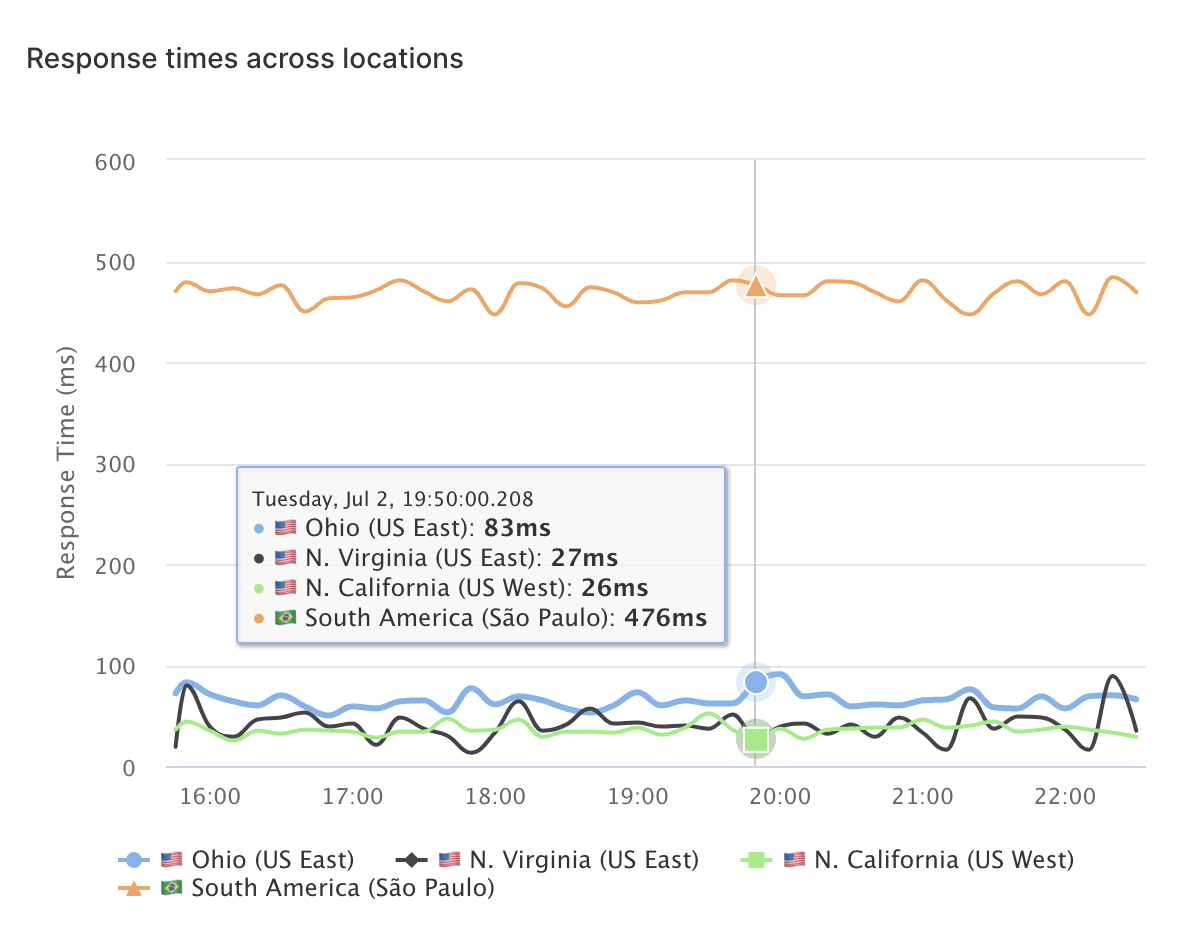
Überwachen Sie die Verfügbarkeit und Reaktionszeiten von APIs aus mehreren globalen Cloud-Standorten.
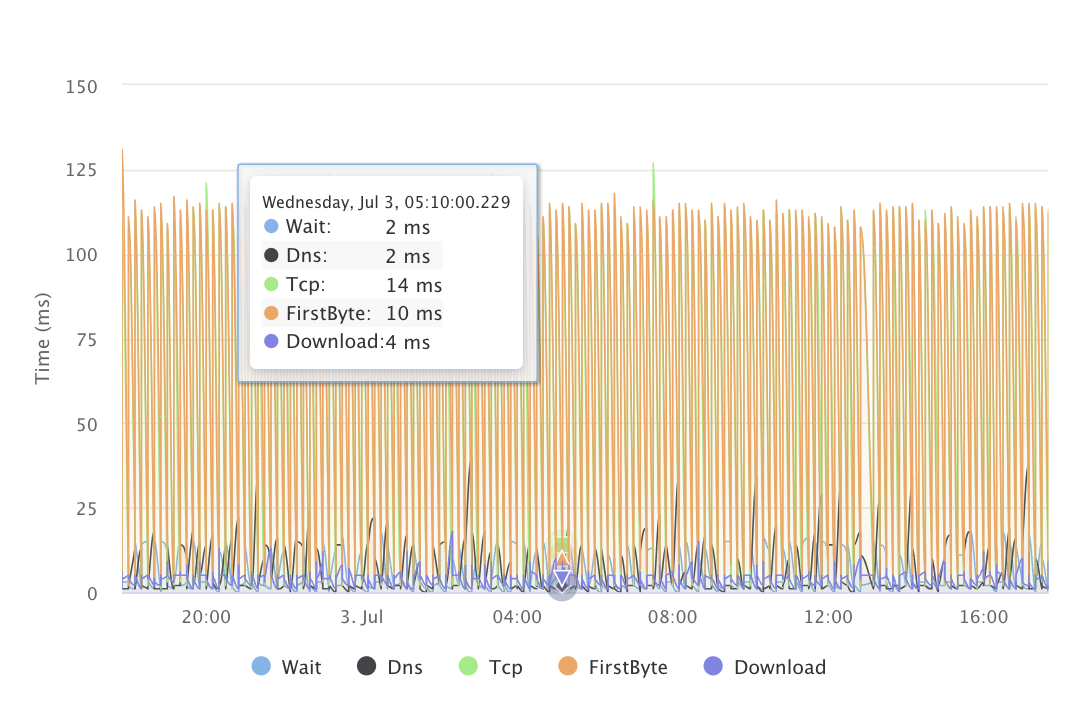
Echtzeit-Anomalieerkennung
Identifizieren und lösen Sie API-Probleme schnell.
Überwachen von API-Vereinbarungen
Behalten Sie SLAs im Auge und stellen Sie sicher, dass Ihre APIs die erwarteten Leistungsstandards erfüllen.
Wählen Sie LoadFocus für die API-Überwachung 🚀
Auf der Suche nach detaillierten API-Einblicken?
Benutzer vertrauen uns für eine umfassende, Echtzeit-Überwachung der API-Leistung.
Umfangreiche API-Metriken
Über grundlegende Checks hinaus bietet LoadFocus tiefe Einblicke in die Gesundheit und Leistung von APIs.
Intuitive Benutzeroberfläche
Unsere Plattform ist benutzerfreundlich und ermöglicht ein einfaches Verständnis und Management der API-Gesundheit.
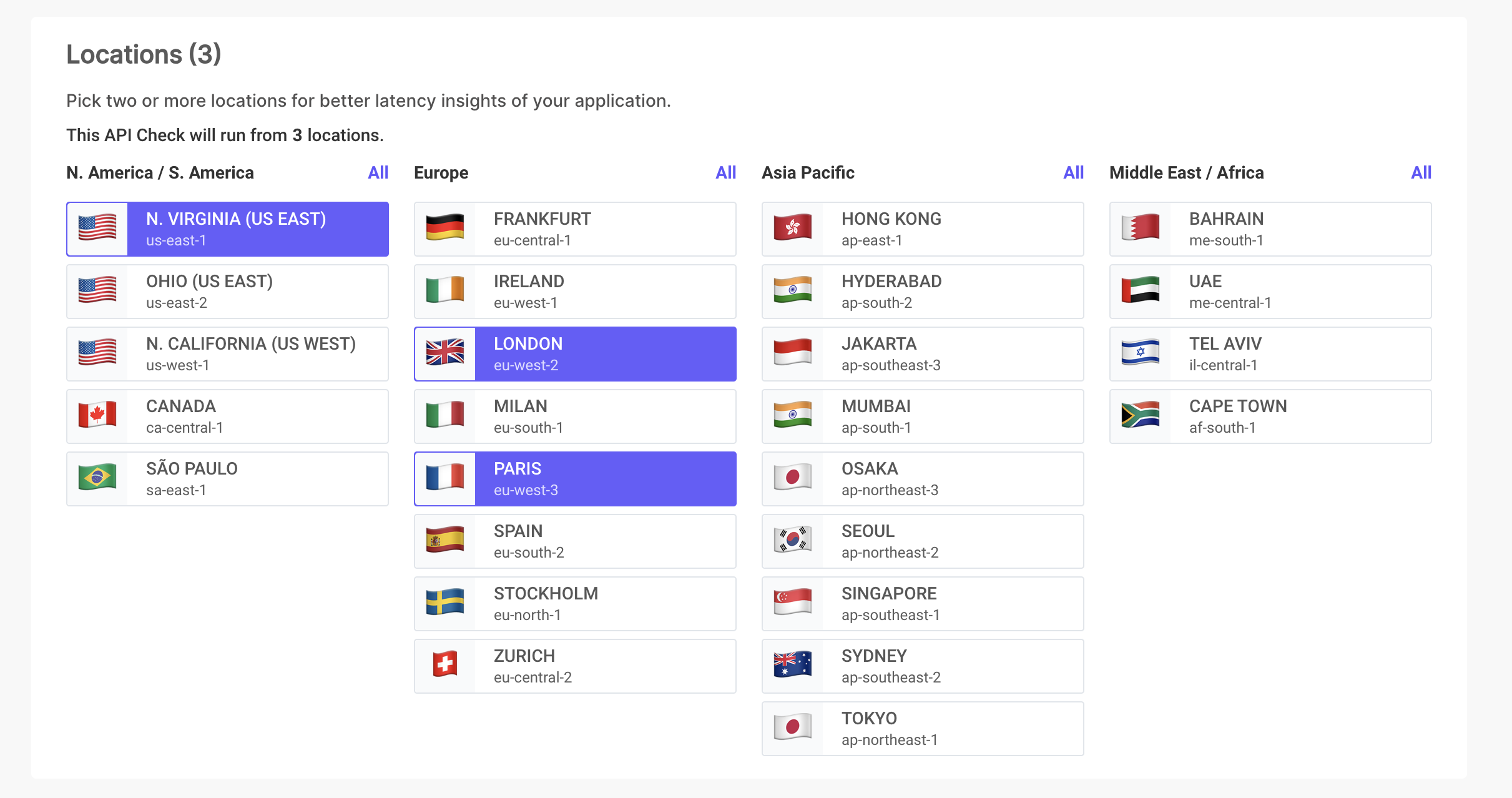
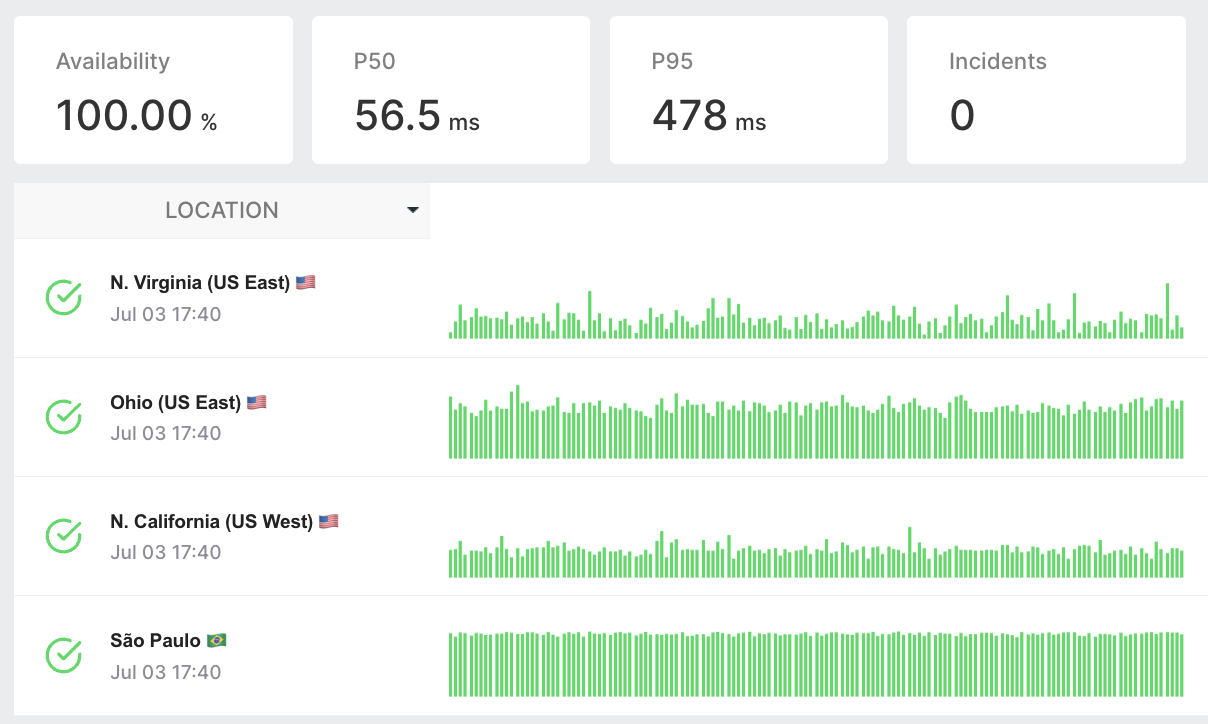
Globales API-Monitoring 🌍
Interessiert an der globalen Leistung Ihrer APIs?
Unternehmen weltweit nutzen LoadFocus, um die API-Performance in verschiedenen Regionen zu überwachen.
Vielfältige Überwachungsorte
Testen und überwachen Sie Ihre APIs von verschiedenen Standorten aus, um eine globale Leistungskonsistenz sicherzustellen.
Optimierung für weltweite Reichweite
Passen Sie Ihre APIs an, um ein internationales Publikum effektiv zu bedienen und stellen Sie sicher, dass sie überall zuverlässig sind.
Browser-Checks und mehrstufige API-Flows
Brechen Ihre Benutzer-Flows zwischen API-Aufrufen ab?
Spielen Sie echte Playwright-Skripte in 26 Regionen ab, um Fehler bei Login, Checkout und anderen kritischen Pfaden zu erkennen, bevor Ihre Nutzer es tun.
Verkettete Anfragen mit Datenweitergabe
Uebergeben Sie Werte von einem Schritt zum naechsten: Ziehen Sie einen Token aus der Login-Antwort und injizieren Sie ihn in den naechsten Request-Header. Keine Umwege ueber Scripting noetig.
Wiederverwendbare Code-Snippets
Teilen Sie gemeinsame Logik ueber Checks hinweg mit require('./snippets/name'). Snippet einmal aktualisieren und jeder Check, der es verwendet, uebernimmt die Aenderung.
TCP-, DNS- und Heartbeat-Monitore
Muessen Sie mehr als HTTP ueberwachen?
TCP-Monitore pruefen, ob ein Port offen und erreichbar ist. DNS-Monitore bestaetigen, dass Ihre Records aus 26 Regionen auf die richtigen Werte aufgeloest werden.
Heartbeat- und Cron-Job-Monitoring
Senden Sie einen Ping, nachdem jeder geplante Job ausgefuehrt wurde. Bleibt der Ping aus, benachrichtigt LoadFocus Sie. Erkennt stille Fehler in Hintergrundprozessen, Datenpipelines und Batch-Jobs.
Fehler entdecken, die HTTP-Checks uebersehen
Ein TCP-Check sagt Ihnen, ob der Datenbankport offen ist. Ein DNS-Check erkennt Propagierungsprobleme. Ein Heartbeat-Check sagt Ihnen, ob das naechliche Backup wirklich abgeschlossen wurde.
Status Pages, Dashboards und Check-Gruppen
Moechten Sie alle Ihre Service-Status in einer Ansicht sehen?
Oeffentliche und private Status Pages zeigen Echtzeit-Uptime, Incident-Verlauf und Response-Time-Charts. Informieren Sie Ihre Kunden sofort, wenn ein Incident beginnt.
Check-Gruppen und Wartungsfenster
Fassen Sie zusammenhaengende Checks zu Gruppen zusammen und stumm schalten Sie Alerts waehrend geplanter Wartungsfenster. Kein Alert-Storm bei Deployments, keine falschen Benachrichtigungen an Ihr On-Call-Team.
Dashboards fuer jedes Team
Geteilte Dashboards zeigen die Checks, die Ihr Team benoetigt. Alle Metriken in einer Ansicht, von API-Antwortzeiten bis zu Uptime-Prozentsaetzen ueber Regionen.
Monitoring as Code und OpenAPI-Import
Moechten Sie Ihre Monitore so verwalten wie Ihre Infrastruktur?
Definieren Sie Checks in YAML oder JSON und uebertragen Sie sie per API oder CLI. Versionieren Sie Ihre Monitoring-Konfiguration zusammen mit Ihrem Code und rollen Sie Monitoraenderungen in CI aus.
OpenAPI- und Swagger-Import
Zeigen Sie LoadFocus auf eine OpenAPI-3.x- oder Swagger-2.0-Spezifikation und es wird automatisch ein Monitor pro Operation erstellt. Kein manuelles Einrichten fuer jeden Endpoint.
Konsistente Abdeckung von Anfang an
Neue Endpoints, die Ihrer Spezifikation hinzugefuegt werden, erhalten beim naechsten Import Monitore. Geloeschte Endpoints werden bereinigt. Ihr Monitoring bleibt mit Ihrer API synchron, wie sie sich weiterentwickelt.