Optimisez les performances de votre API
Vos API répondent-elles lentement?
Une mauvaise performance de l'API peut avoir un impact sur l'expérience utilisateur et les opérations commerciales.
Repérez les problèmes de performance avec précision.
Analysez les mesures de l'API, validez les charges utiles et suivez les temps de réponse.
Solutions pour des API robustes
Utilisez LoadFocus pour des conseils complets sur l'amélioration des performances et de la fiabilité de l'API.
Avantages de la surveillance en temps réel de l'API
Pourquoi se concentrer sur la surveillance de l'API?
Des API efficaces améliorent l'expérience utilisateur et les flux de travail de l'entreprise.
Stratégies de surveillance sur mesure
Obtenez des informations spécifiques sur les performances de votre API et les domaines à améliorer.
Au-delà de la vitesse et du temps de disponibilité
Utilisez LoadFocus pour améliorer la fiabilité de l'API, réduire les temps d'arrêt et améliorer la qualité globale du service.
Analyse complète de la santé de l'API
Assurez-vous que vos API sont toujours en fonctionnement.
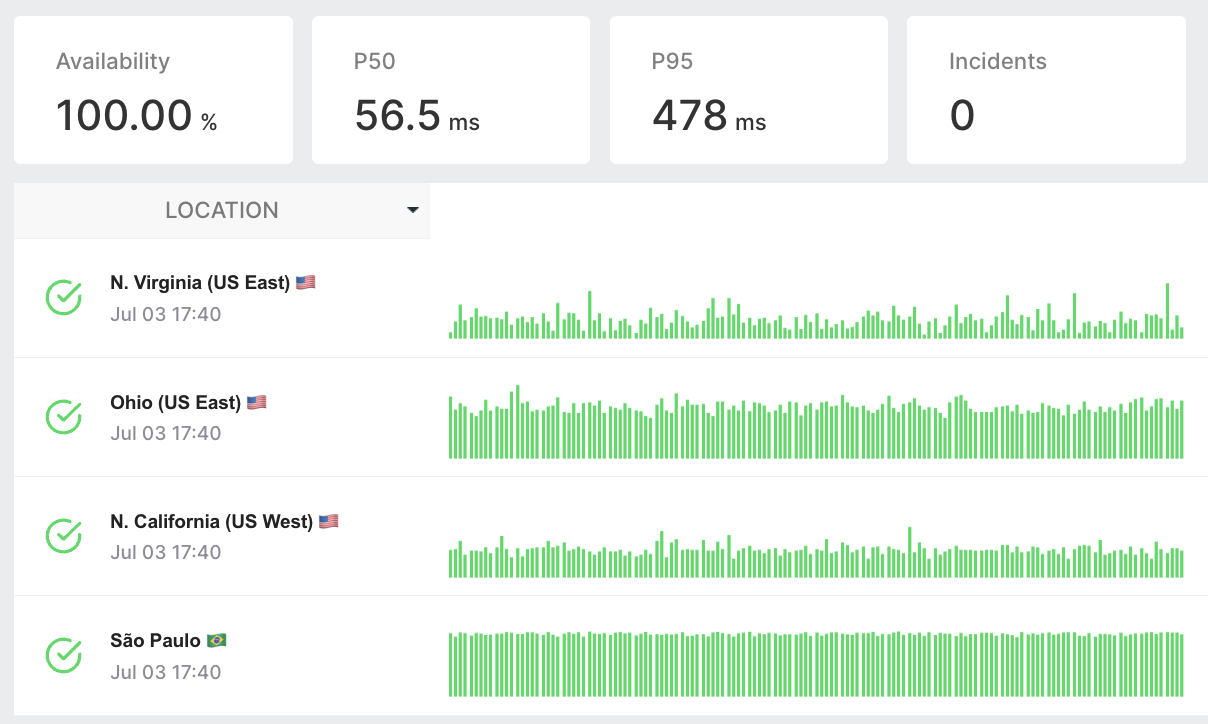
Surveillez la disponibilité et les temps de réponse des API à partir de plusieurs emplacements cloud mondiaux.
Détection d'anomalies en temps réel
Identifiez et résolvez rapidement les problèmes d'API.
Surveillance des accords API
Suivez les SLA et assurez-vous que vos API respectent les normes de performance attendues.
Choisissez LoadFocus pour la surveillance des API 🚀
Vous recherchez des informations détaillées sur les API?
Les utilisateurs nous font confiance pour une surveillance approfondie et en temps réel des performances des API.
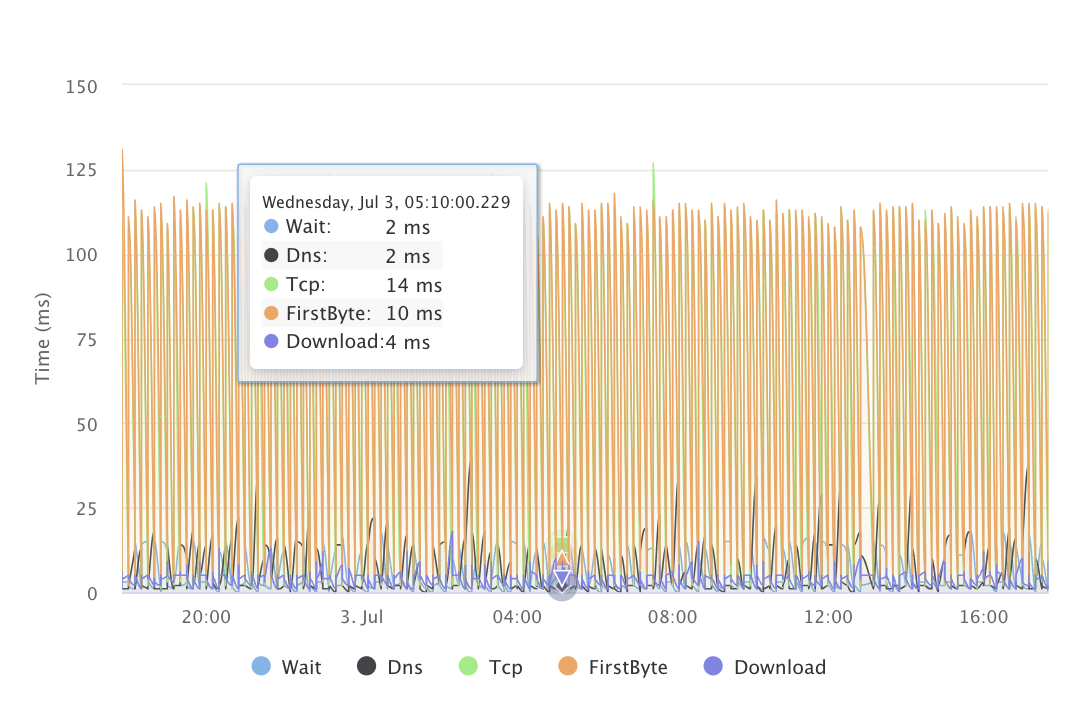
Extensive API Metrics
Au-delà des vérifications de base, LoadFocus offre des informations approfondies sur la santé et les performances de l'API.
Interface intuitive
Notre plateforme est conviviale, permettant une compréhension et une gestion faciles de la santé de l'API.
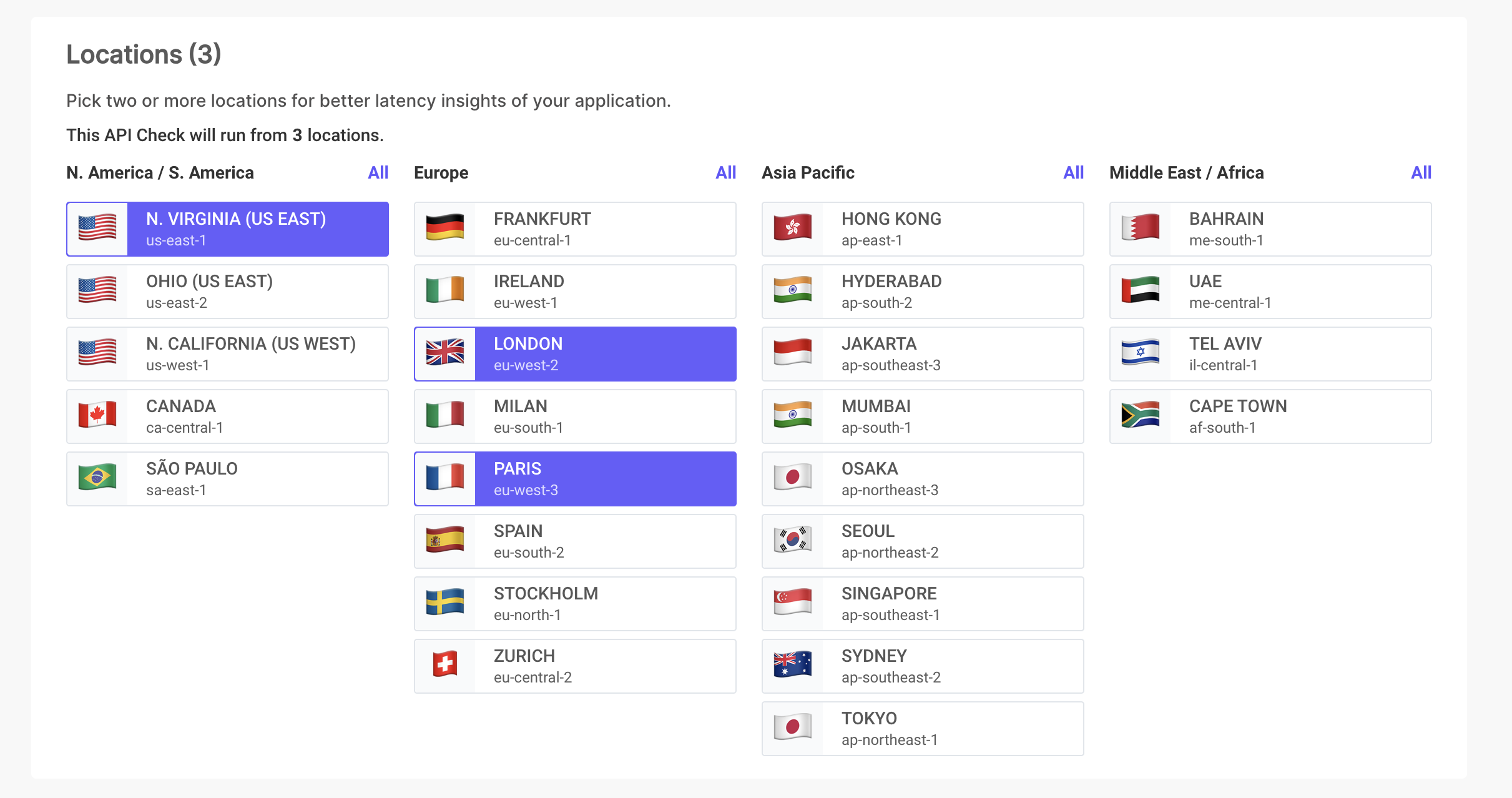
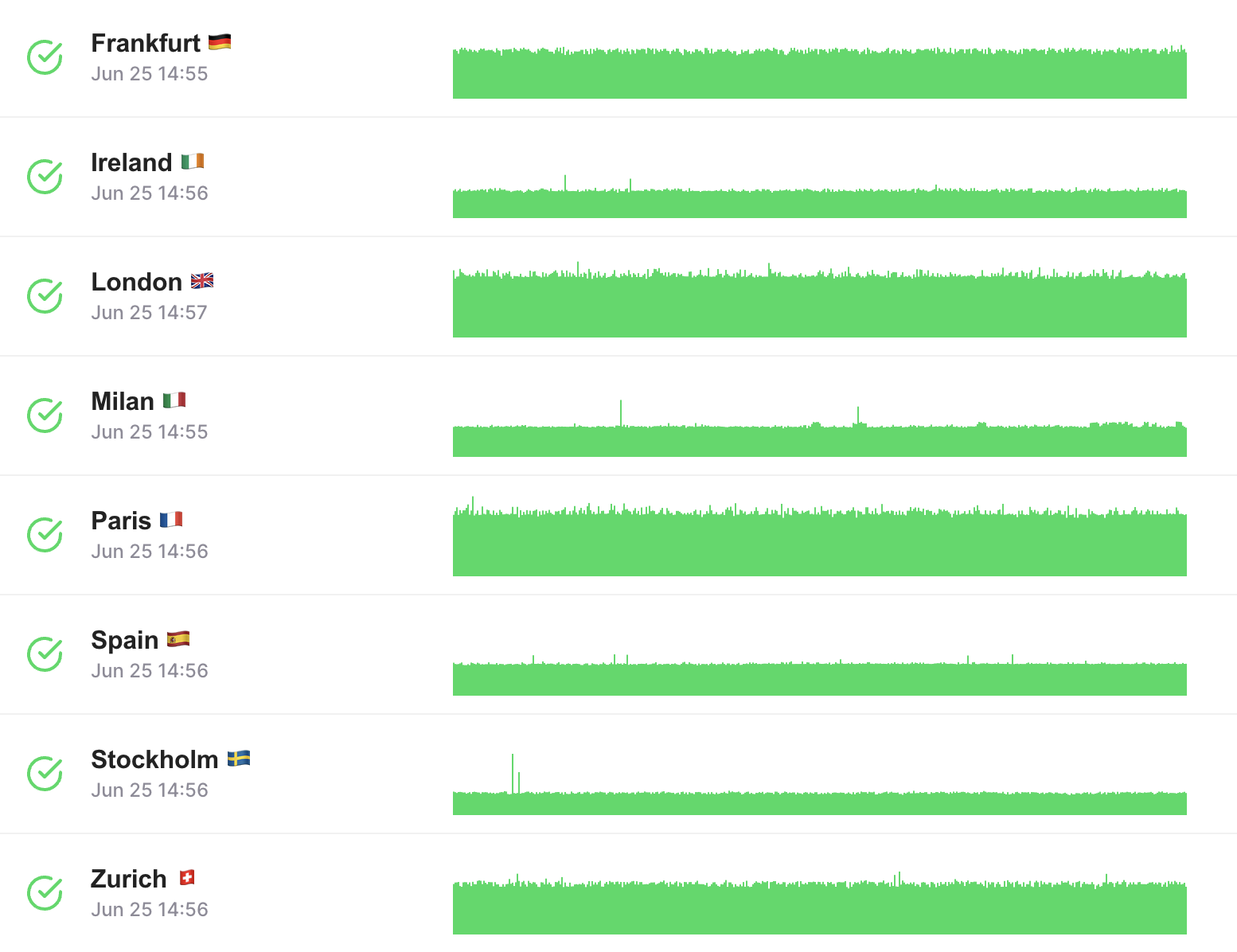
Surveillance mondiale de l'API 🌍
Curieux de savoir comment vos API se comportent à l'échelle mondiale?
Les entreprises du monde entier utilisent LoadFocus pour surveiller les performances de l'API dans différentes régions.
Emplacements de surveillance diversifiés
Testez et surveillez vos API à partir de différents endroits pour garantir une cohérence des performances à l'échelle mondiale.
Optimisez pour une portée mondiale
Ajustez vos APIs pour servir efficacement un public international, en veillant à leur fiabilité partout.
Checks navigateur et flux API multi-étapes
Vos flux utilisateur se cassent-ils entre des appels API ?
Rejouez des scripts Playwright réels dans 26 régions pour détecter les pannes lors du login, du checkout et d'autres parcours critiques avant que vos utilisateurs ne le fassent.
Requêtes chaînées avec transfert de données
Transmettez des valeurs d'une étape à la suivante : extrayez un token de la réponse de login et injectez-le dans le header de la prochaine requête. Pas besoin de contournements de scripting.
Snippets de code réutilisables
Partagez la logique commune entre les checks avec require('./snippets/nom'). Mettez à jour le snippet une fois et chaque check qui l'utilise récupère le changement.
Moniteurs TCP, DNS et Heartbeat
Avez-vous besoin de surveiller plus que le HTTP ?
Les moniteurs TCP vérifient qu'un port est ouvert et accepte des connexions. Les moniteurs DNS confirment que vos enregistrements se résolvent aux bonnes valeurs depuis 26 régions.
Monitoring heartbeat et cron jobs
Envoyez un ping après chaque exécution de tâche planifiée. Si le ping cesse d'arriver, LoadFocus vous alerte. Détecte les échecs silencieux dans les processus d'arrière-plan, les pipelines de données et les traitements par lots.
Détectez ce que les checks HTTP manquent
Un check TCP vous dit si le port de la base de données est ouvert. Un check DNS détecte les problèmes de propagation. Un check heartbeat vous dit si la sauvegarde nocturne s'est vraiment terminée.
Pages de statut, tableaux de bord et groupes de checks
Voulez-vous une vue unique de la santé de tous vos services ?
Les pages de statut publiques et privées affichent l'uptime en temps réel, l'historique des incidents et des graphiques de temps de réponse. Informez vos clients dès qu'un incident commence.
Groupes de checks et fenêtres de maintenance
Regroupez les checks liés et mutelez les alertes pendant les fenêtres de maintenance planifiées. Pas de tempêtes d'alertes lors des déploiements, pas de fausses pages à votre équipe d'astreinte.
Tableaux de bord pour chaque équipe
Les tableaux de bord partagés affichent les checks qui comptent pour votre équipe. Toutes les métriques en une vue, des temps de réponse API aux pourcentages d'uptime par région.
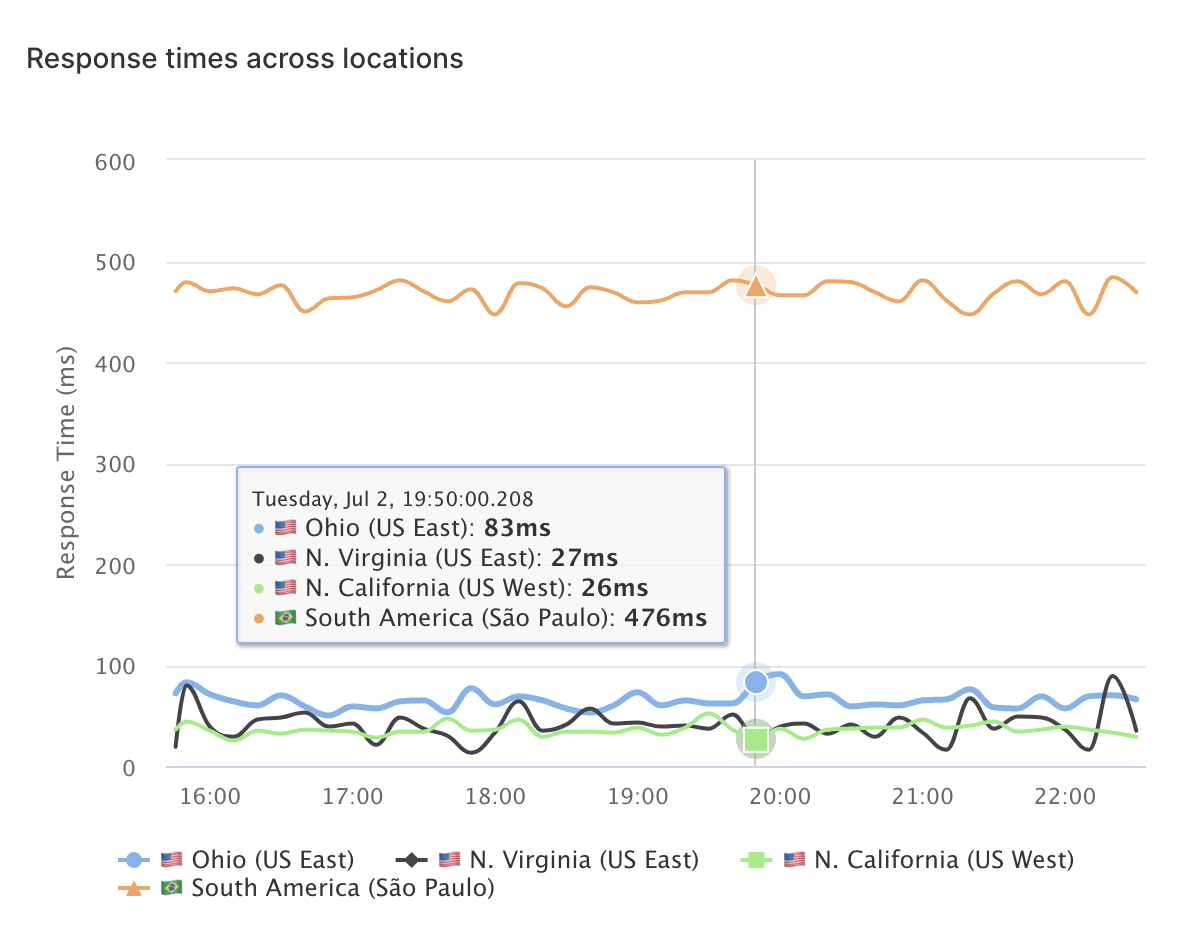
Monitoring as Code et import OpenAPI
Voulez-vous gérer vos moniteurs comme vous gérez votre infrastructure ?
Définissez des checks en YAML ou JSON et poussez-les via l'API ou la CLI. Versionnez votre config de monitoring avec votre code et déployez les changements de moniteurs en CI.
Import OpenAPI et Swagger
Pointez LoadFocus vers une spec OpenAPI 3.x ou Swagger 2.0 et il génère automatiquement un moniteur par opération. Pas de configuration manuelle pour chaque endpoint.
Couverture cohérente dès le premier jour
Les nouveaux endpoints ajoutés à votre spec reçoivent des moniteurs au prochain import. Les endpoints supprimés sont nettoyés. Votre monitoring reste synchronisé avec votre API à mesure qu'elle évolue.