Pruebas de carga para APIs de microservicios de alta escalabilidad
Pruebas de carga para APIs de microservicios de alta escalabilidad están diseñadas para simular miles de usuarios virtuales desde más de 26 regiones en…
Los microservicios cambian la superficie de fallo. Un monolito bajo carga se ralentiza; una malla de servicios bajo carga se ramifica, una llamada lenta aguas abajo bloquea hilos de worker aguas arriba, los pools se vacían, los reintentos se acumulan, y una sola dependencia se lleva por delante el cluster. Esta plantilla carga los saltos entre servicios tal y como el tráfico de producción los configura, no como impactos aislados a endpoints.
Qué prueba
Los scripts escalan desde la línea base de RPS hasta 2x y 5x en estado estable, manteniendo cada escalón 8-12 minutos para que pools de conexiones, asignaciones del runtime de JVM/Go y decisiones del HPA se estabilicen. Tamaños de payload mixtos, tokens de auth reales por usuario virtual, y llamadas encadenadas, gateway, auth, dos o tres servicios aguas abajo, después una escritura, ejercitando el mismo grafo de llamadas que sus traces muestran en producción.
Modos de fallo que vale la pena cazar
- Agotamiento del pool de conexiones en la capa de gateway o BFF, los límites de HTTP keep-alive se alcanzan antes que la CPU. Vigile las conexiones activas, no solo la CPU.
- Cascada por servicio lento aguas abajo: un servicio añade 400ms p95 y tres servicios aguas arriba se despeñan tras él porque sus timeouts por request son 2s pero el tamaño de pool es 50.
- Tormentas de reintentos: backoff exponencial bienintencionado sin jitter, golpeando un servicio ya degradado en sincronía.
- Aleteo del circuit breaker: las sondas half-open disparan en el mismo instante desde cada réplica.
- Límites de stream de gRPC HTTP/2:
MAX_CONCURRENT_STREAMSpor defecto es 100 en la mayoría de servidores; un cliente REST de alto RPS con una conexión por pod no lo alcanzará, un cliente gRPC sí.
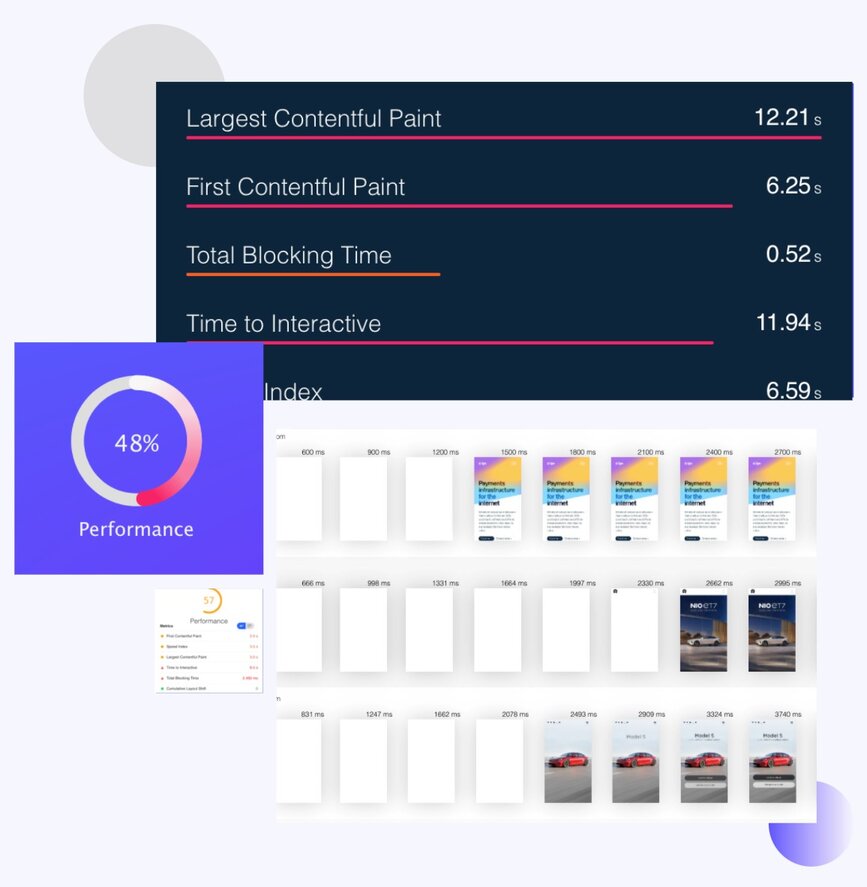
Objetivos de latencia con sentido
Rastree p50, p95, p99 por salto, no solo extremo a extremo. Un punto de partida para tráfico east-west: p99 por debajo de 50ms para lecturas de caché, por debajo de 150ms para lecturas contra BD, por debajo de 300ms para saltos entre servicios que a su vez se ramifican. Un p99 extremo a extremo de 1s está bien para un checkout que toca ocho servicios; pésimo para un endpoint de status que toca uno. La quema del error budget importa más que la tasa de error bruta. 0.5% durante un pico de 5 minutos no es 0.5% sostenido.
Cómo ejecutarla
La plantilla viene en variantes JMeter y k6. k6 encaja mejor para HTTP/2, gRPC y grafos de request scripteados; JMeter es la opción más segura si ya tiene una librería JMX en la que confía. Ejecute desde LoadFocus a través de varias de las 26+ regiones cloud para que la latencia inter-región aparezca en sus números, los tests mono-región sub-reportan sistemáticamente la latencia de cola en servicios globales.
Conecte la ejecución al CI: Jenkins, Azure Pipelines o CircleCI pueden disparar una ejecución a escala smoke en cada merge a main y una a escala completa cada noche. Falle el build por regresión de p99 o quema de error budget, no por umbrales absolutos, los absolutos derivan, los deltas no mienten.
Lectura de resultados
Las gráficas en tiempo real cazan lo obvio, throughput plano cuando los RPS suben significa saturación aguas arriba del generador de carga, latencia en diente de sierra significa GC o autoscaling. El trabajo post-ejecución es correlacionar tiempos con traces de APM y métricas de pod: qué servicio movió primero su p99, qué hizo la profundidad de su pool, si su downstream se ralentizó o solo recibió la culpa.
La plantilla, los scripts y el historial de ejecuciones viven en LoadFocus, clónela, apunte las variables a su gateway, fije la concurrencia y déjela correr.
¿Qué tan rápido es tu sitio web?
Mejora su velocidad y SEO sin problemas con nuestra Prueba de Velocidad gratuita.¿Tus herramientas de prueba se han quedado pequeñas?
Haz load testing de sitios web y APIs desde 25+ regiones en la nube, monitorea la velocidad de página y el uptime, y recibe análisis con AI que explican tus resultados en lenguaje claro.Comience a probar ahora→