Optimizar el rendimiento de su API
¿Sus APIs están respondiendo lentamente?
Un mal rendimiento de la API puede afectar la experiencia del usuario y las operaciones comerciales.
Identificar problemas de rendimiento
Analizar métricas de API, validar cargas y rastrear tiempos de respuesta.
Soluciones para APIs robustas
Utilice LoadFocus para obtener asesoramiento completo sobre cómo mejorar el rendimiento y la confiabilidad de la API.
Ventajas del monitoreo de API en tiempo real
¿Por qué enfocarse en el monitoreo de API?
Las APIs eficientes mejoran la experiencia del usuario y los flujos de trabajo comerciales.
Estrategias de monitoreo personalizadas
Obtenga información específica sobre el rendimiento de su API y áreas de mejora.
Más allá de la velocidad y el tiempo de actividad
Utilice LoadFocus para mejorar la confiabilidad de la API, reducir los tiempos de inactividad y mejorar la calidad del servicio en general.
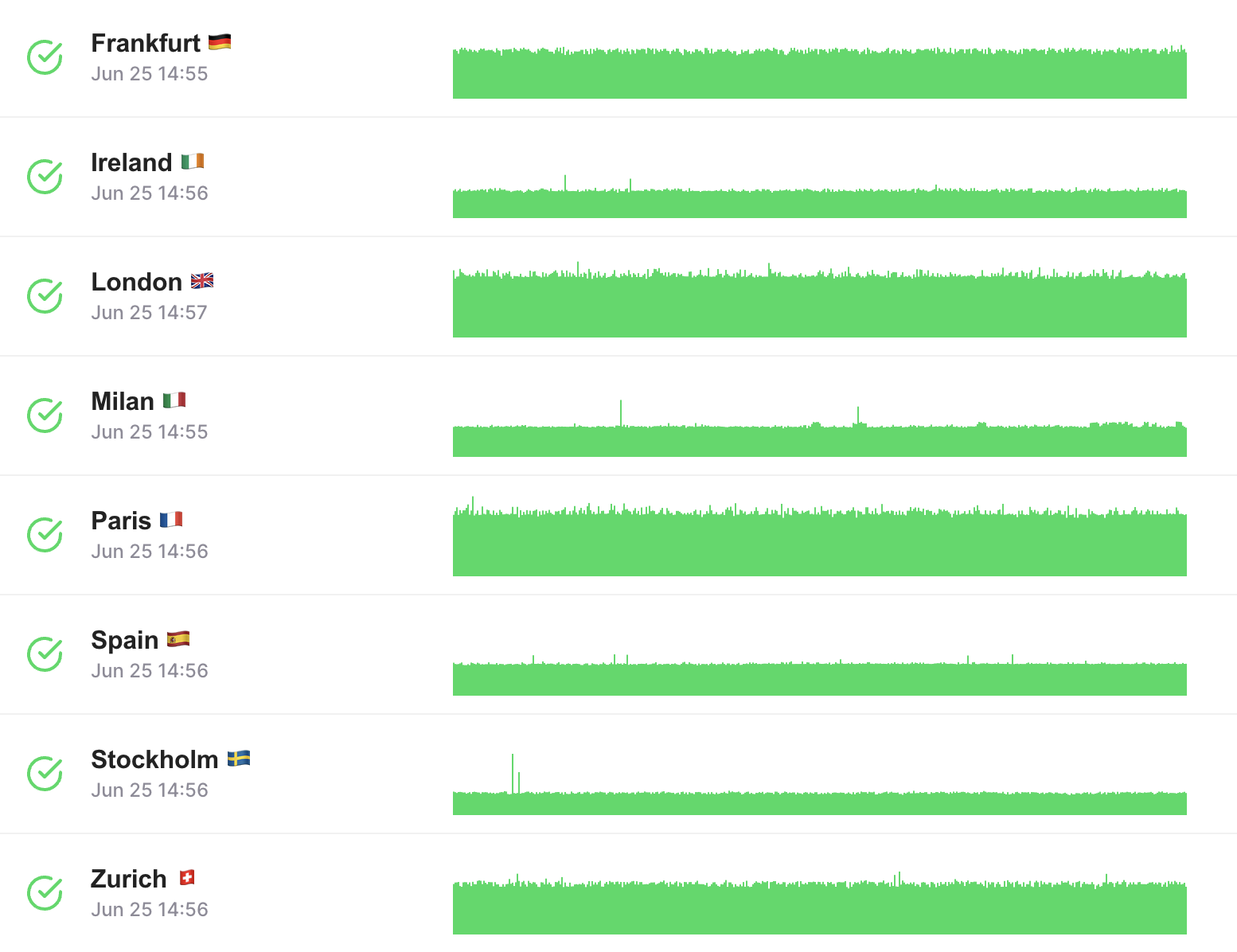
Análisis completo de salud de la API
Asegúrese de que sus APIs siempre estén funcionando.
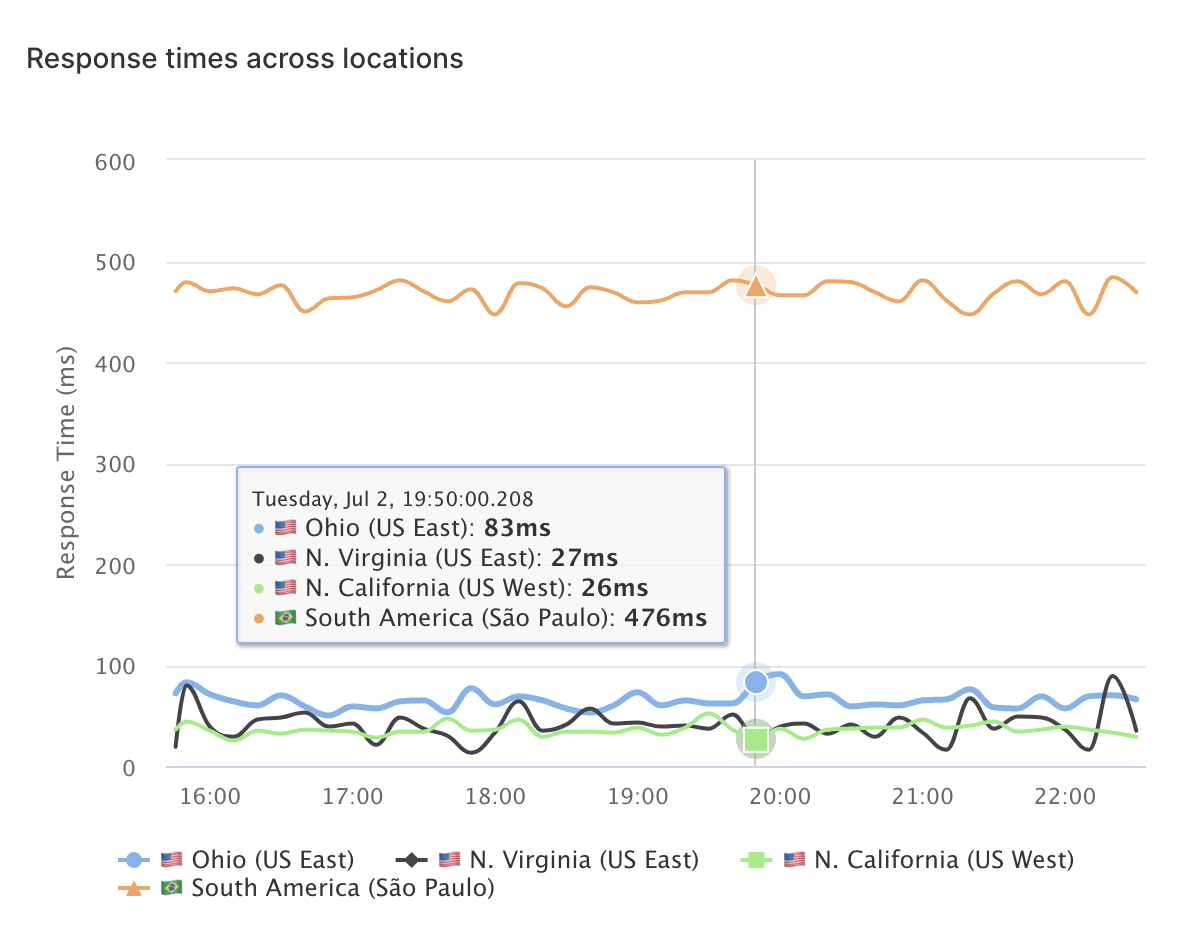
Monitoree la disponibilidad y los tiempos de respuesta de las APIs desde múltiples ubicaciones globales en la nube.
Detección de anomalías en tiempo real
Identifique y resuelva rápidamente problemas de API.
Monitoreo de acuerdos de API
Mantenga un registro de los SLAs y asegúrese de que sus APIs cumplan con los estándares de rendimiento esperados.
Elija LoadFocus para el monitoreo de APIs 🚀
¿Buscando información detallada sobre APIs?
Los usuarios confían en nosotros para el monitoreo de rendimiento en tiempo real de APIs.
Métricas de API extensivas
Más allá de las comprobaciones básicas, LoadFocus ofrece información profunda sobre la salud y el rendimiento de la API.
Interfaz intuitiva
Nuestra plataforma es fácil de usar, lo que permite una comprensión y gestión sencilla de la salud de la API.
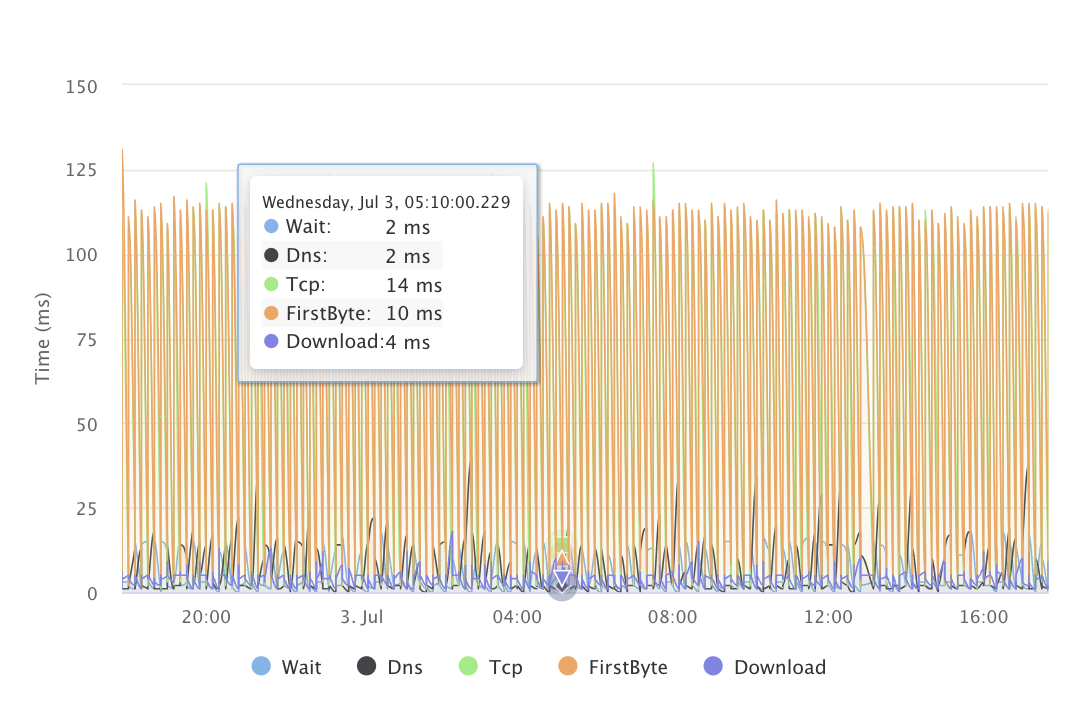
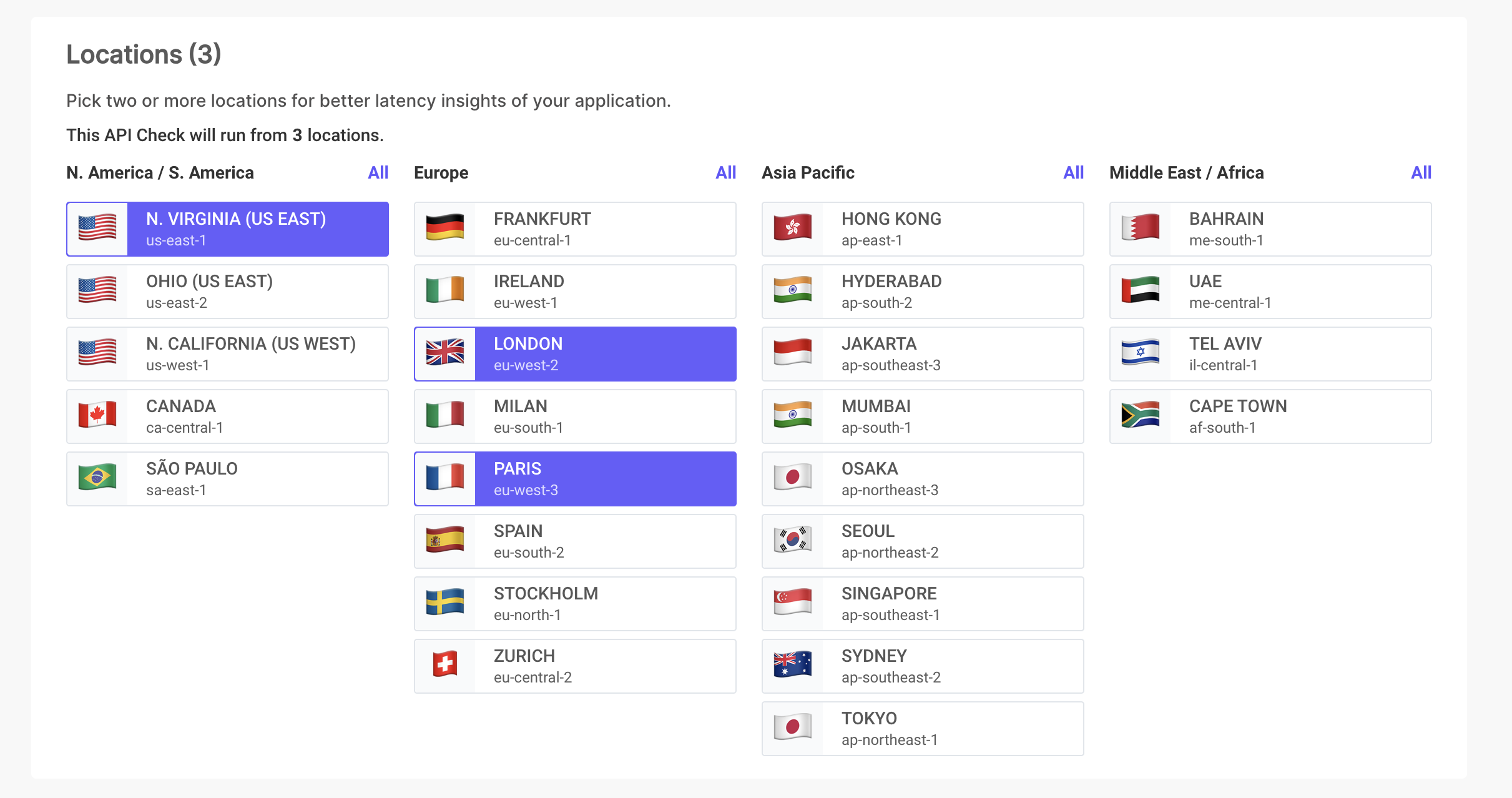
Monitoreo global de API 🌍
¿Curioso acerca de cómo funcionan tus APIs a nivel global?
Empresas de todo el mundo utilizan LoadFocus para monitorear el rendimiento de la API en diferentes regiones.
Ubicaciones de monitoreo diversas
Prueba y monitorea tus APIs desde diferentes ubicaciones para garantizar una consistencia de rendimiento global.
Optimiza para alcanzar a nivel mundial
Ajusta tus APIs para servir a una audiencia internacional de manera efectiva, asegurando su fiabilidad en todo lugar.
Checks de navegador y flujos API de varios pasos
¿Se rompen tus flujos de usuario entre llamadas API?
Reproduce scripts reales de Playwright en 26 regiones para detectar fallos en login, checkout y otras rutas críticas antes de que lo hagan tus usuarios.
Peticiones encadenadas con traspaso de datos
Pasa valores de un paso al siguiente: extrae un token de la respuesta de login e inyéctalo en la cabecera de la siguiente petición. Sin necesidad de rodeos de scripting.
Fragmentos de código reutilizables
Comparte lógica común entre checks con require('./snippets/nombre'). Actualiza el snippet una vez y todos los checks que lo usan recogen el cambio.
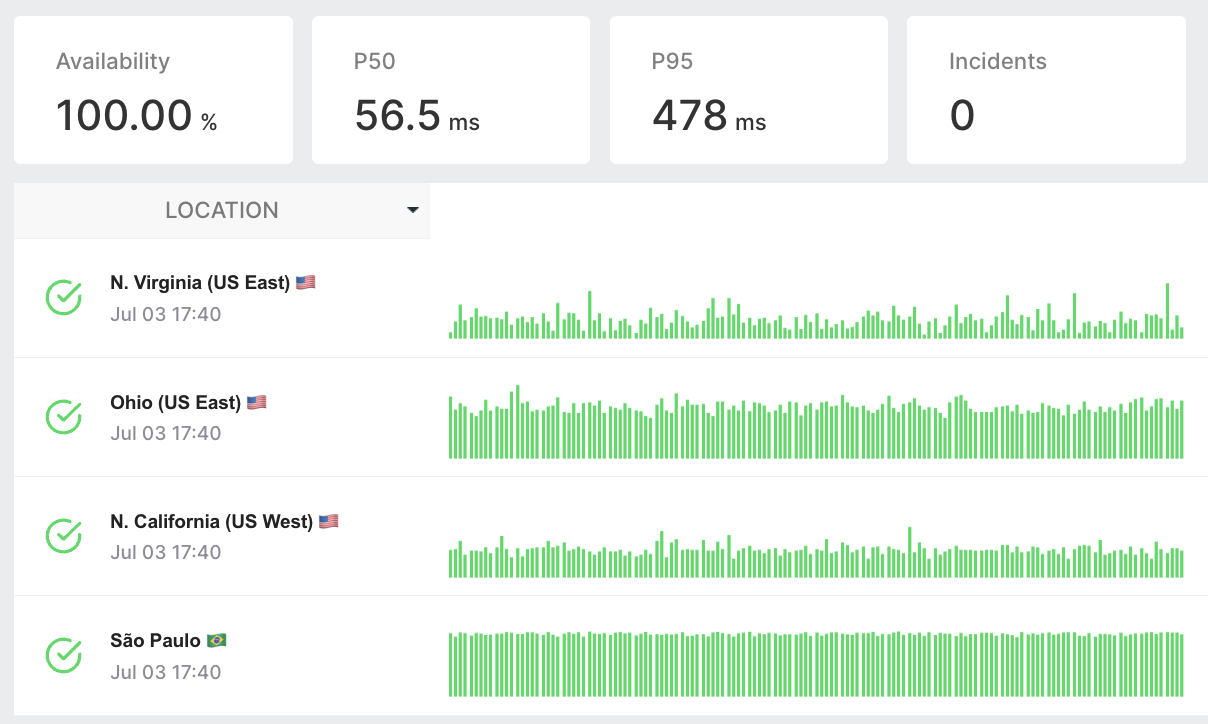
Monitores TCP, DNS y Heartbeat
¿Necesitas monitorizar más que HTTP?
Los monitores TCP verifican que un puerto está abierto y acepta conexiones. Los monitores DNS confirman que tus registros se resuelven a los valores correctos desde 26 regiones.
Monitorización de heartbeat y cron jobs
Envía un ping tras cada ejecución de un trabajo programado. Si el ping deja de llegar, LoadFocus te alerta. Detecta fallos silenciosos en procesos en segundo plano, pipelines de datos y procesos por lotes.
Detecta lo que los checks HTTP se pierden
Un check TCP te dice si el puerto de la base de datos está abierto. Un check DNS detecta problemas de propagación. Un check de heartbeat te dice si el backup nocturno realmente terminó.
Páginas de estado, dashboards y grupos de checks
¿Quieres una vista única de la salud de todos tus servicios?
Las páginas de estado públicas y privadas muestran uptime en tiempo real, historial de incidentes y gráficas de tiempo de respuesta. Informa a tus clientes en el momento en que comienza un incidente.
Grupos de checks y ventanas de mantenimiento
Agrupa checks relacionados y silencia alertas durante ventanas de mantenimiento planificadas. Sin tormentas de alertas en los despliegues, sin falsas páginas a tu equipo de guardia.
Dashboards para cada equipo
Los dashboards compartidos muestran los checks que le importan a tu equipo. Todas las métricas en una vista, desde tiempos de respuesta de API hasta porcentaje de uptime por región.
Monitoring as Code e importación de OpenAPI
¿Quieres gestionar tus monitores igual que gestionas tu infraestructura?
Define checks en YAML o JSON y envíalos via API o CLI. Controla la versión de tu configuración de monitorización junto con tu código y despliega cambios de monitores en CI.
Importación de OpenAPI y Swagger
Apunta LoadFocus a una especificación OpenAPI 3.x o Swagger 2.0 y genera automáticamente un monitor por operación. Sin configuración manual para cada endpoint.
Cobertura consistente desde el primer día
Los nuevos endpoints añadidos a tu especificación reciben monitores en la próxima importación. Los endpoints eliminados se limpian. Tu monitorización se mantiene sincronizada con tu API a medida que evoluciona.